Code
library(gt)
library(dplyr) # Using dplyr for mutate, optional but convenient
library(gtExtras) # For image embeddingA guide to creating visually appealing tables in R and Python using the gt and great_tables packages, with examples of styling, image embedding, and nanoplots.
This document provides a comprehensive guide to creating visually appealing and informative tables in both R and Python. It focuses on the gt package in R and the great_tables package in Python, demonstrating how to style tables, embed images, handle missing data, and even incorporate nanoplots (bar charts) directly into table cells. The guide also includes a practical example of translating great_tables code from Python to R, making it a valuable resource for users of both languages.
With the gt package, anyone can make wonderful-looking tables using the R/Python programming language.
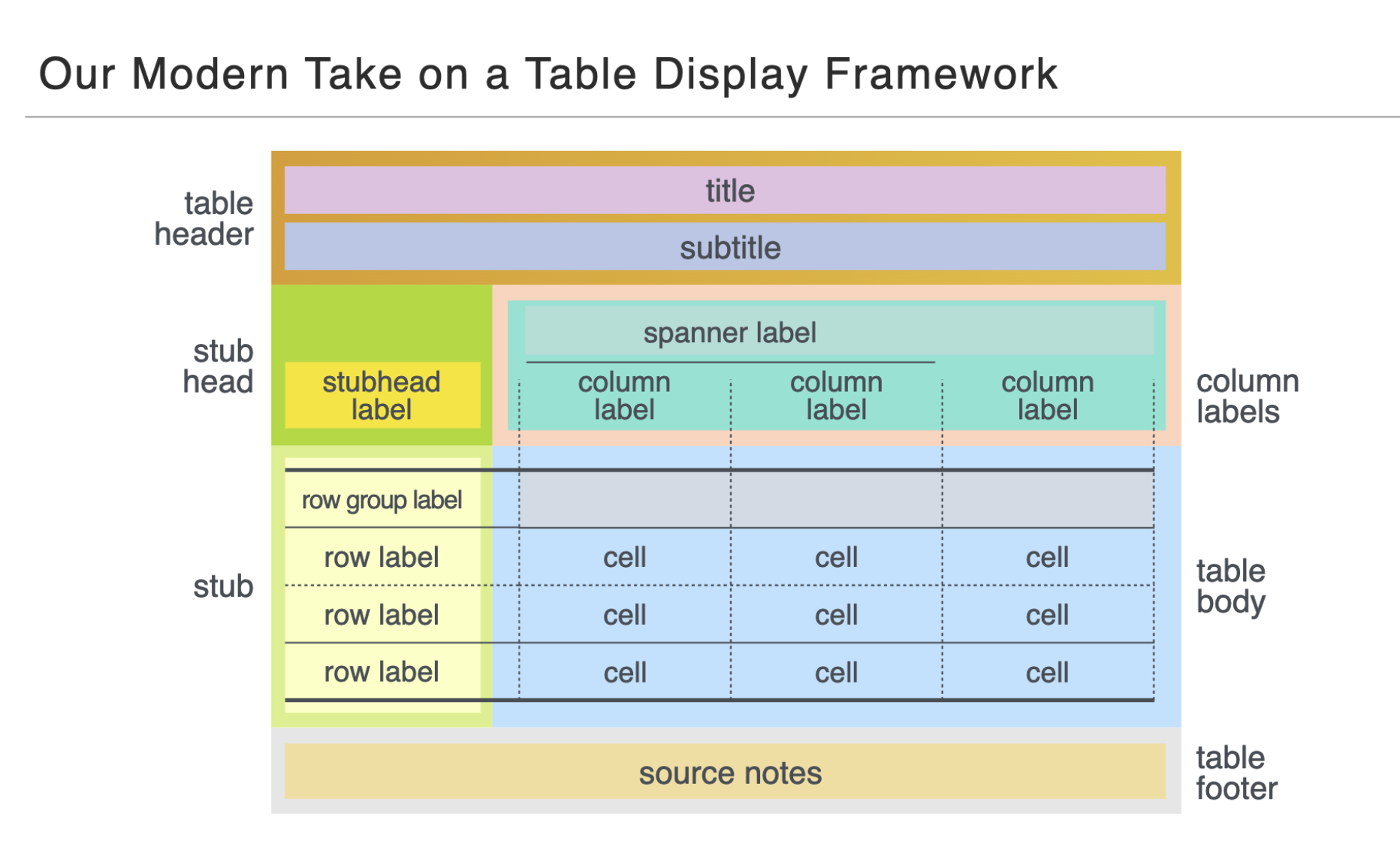

library(gt)
library(dplyr) # Using dplyr for mutate, optional but convenient
library(gtExtras) # For image embeddinglibrary(reticulate)
py_require(c("polars","great-tables","pandas","pyarrow"))exibble |> gt() |> opt_stylize(style=3,color = "green") |> fmt_auto()| num | char | fctr | date | time | datetime | currency | row | group |
|---|---|---|---|---|---|---|---|---|
| 0.111 | apricot | one | 2015-01-15 | 13:35 | 2018-01-01 02:22 | 49.95 | row_1 | grp_a |
| 2.222 | banana | two | 2015-02-15 | 14:40 | 2018-02-02 14:33 | 17.95 | row_2 | grp_a |
| 33.33 | coconut | three | 2015-03-15 | 15:45 | 2018-03-03 03:44 | 1.39 | row_3 | grp_a |
| 444.4 | durian | four | 2015-04-15 | 16:50 | 2018-04-04 15:55 | 65,100 | row_4 | grp_a |
| 5,550 | NA | five | 2015-05-15 | 17:55 | 2018-05-05 04:00 | 1,325.81 | row_5 | grp_b |
| NA | fig | six | 2015-06-15 | NA | 2018-06-06 16:11 | 13.255 | row_6 | grp_b |
| 777,000 | grapefruit | seven | NA | 19:10 | 2018-07-07 05:22 | NA | row_7 | grp_b |
| 8.880 × 106 | honeydew | eight | 2015-08-15 | 20:20 | NA | 0.44 | row_8 | grp_b |
import polars as pl
import polars.selectors as cs
from great_tables import GT, md,exibble
from great_tables.data import reactions#exibbleGT(exibble).opt_stylize(style=3,color = "green")| num | char | fctr | date | time | datetime | currency | row | group |
|---|---|---|---|---|---|---|---|---|
| 0.1111 | apricot | one | 2015-01-15 | 13:35 | 2018-01-01 02:22 | 49.95 | row_1 | grp_a |
| 2.222 | banana | two | 2015-02-15 | 14:40 | 2018-02-02 14:33 | 17.95 | row_2 | grp_a |
| 33.33 | coconut | three | 2015-03-15 | 15:45 | 2018-03-03 03:44 | 1.39 | row_3 | grp_a |
| 444.4 | durian | four | 2015-04-15 | 16:50 | 2018-04-04 15:55 | 65100.0 | row_4 | grp_a |
| 5550.0 | five | 2015-05-15 | 17:55 | 2018-05-05 04:00 | 1325.81 | row_5 | grp_b | |
| fig | six | 2015-06-15 | 2018-06-06 16:11 | 13.255 | row_6 | grp_b | ||
| 777000.0 | grapefruit | seven | 19:10 | 2018-07-07 05:22 | row_7 | grp_b | ||
| 8880000.0 | honeydew | eight | 2015-08-15 | 20:20 | 0.44 | row_8 | grp_b |
Original table:
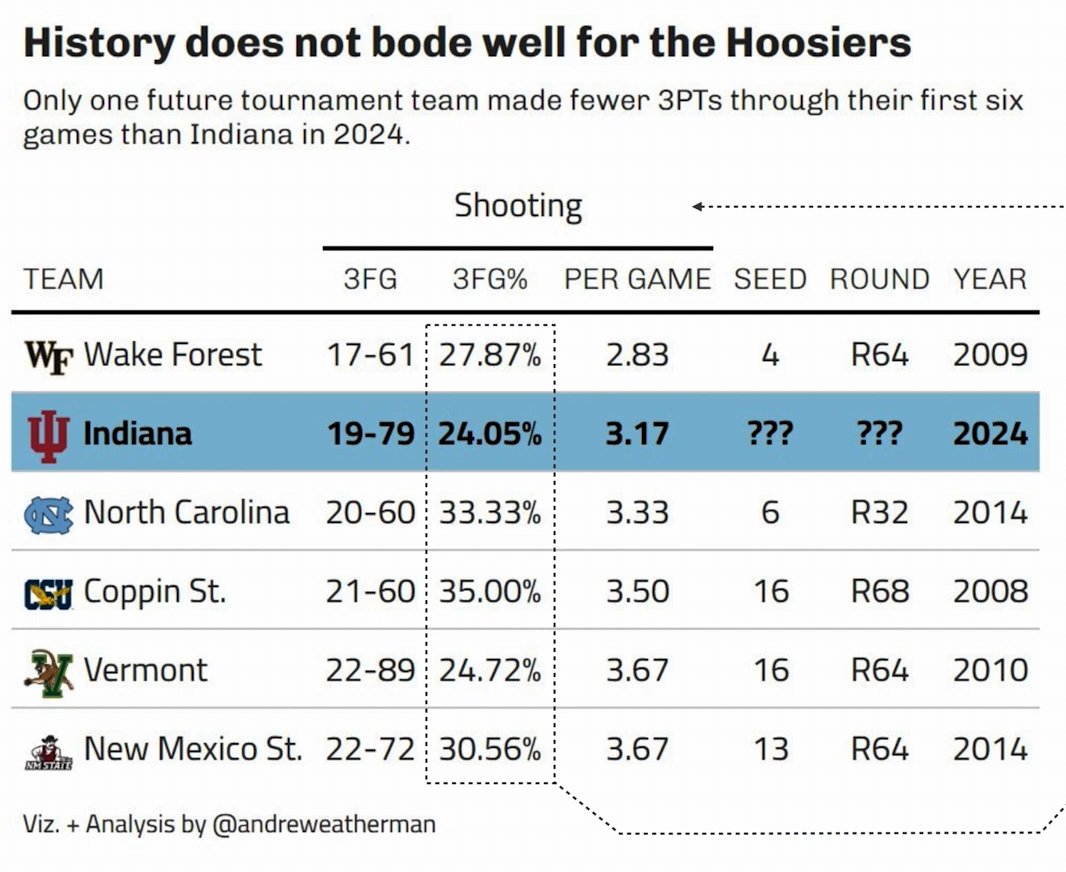
# Load the necessary library
library(gt)
library(dplyr) # Using dplyr for mutate, optional but convenient
library(gtExtras) # For image embedding# 1. Create the data frame
# Note: Storing percentages as numbers (0-100) for easier formatting
hoosiers_data <- data.frame(
TEAM = c("Wake Forest", "Indiana", "North Carolina", "Coppin St.", "Vermont", "New Mexico St."),
logo_url = c(
"https://a.espncdn.com/i/teamlogos/ncaa/500/154.png", # Wake Forest
"https://a.espncdn.com/i/teamlogos/ncaa/500/84.png", # Indiana
"https://a.espncdn.com/i/teamlogos/ncaa/500/153.png", # North Carolina
"https://a.espncdn.com/i/teamlogos/ncaa/500/2154.png", # Coppin St.
"https://a.espncdn.com/i/teamlogos/ncaa/500/261.png", # Vermont
"https://a.espncdn.com/i/teamlogos/ncaa/500/166.png" # New Mexico St.
),
`3FG_Text` = c("17-61", "19-79", "20-60", "21-60", "22-89", "22-72"), # Keep original text for display
`3FG%` = c(27.87, 24.05, 33.33, 35.00, 24.72, 30.56),
PER_GAME = c(2.83, 3.17, 3.33, 3.50, 3.67, 3.67),
SEED = c(4, NA, 6, 16, 16, 13),
ROUND = c("R64", NA, "R32", "R68", "R64", "R64"),
YEAR = c(2009, 2024, 2014, 2008, 2010, 2014),
stringsAsFactors = FALSE # Good practice
)# 2. Create the gt table
gt_table <- hoosiers_data %>%
gt() %>%
# --- Add Logos ---
gt_img_rows(columns = logo_url, height = 25) %>% # Use URL column, set image height
# --- Move logo column ---
cols_move_to_start(columns = logo_url) %>% # Place logo column first
# Add title and subtitle
tab_header(
title = "History does not bode well for the Hoosiers",
subtitle = "Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024."
) %>%
# Create the spanner header over the shooting columns
tab_spanner(
label = "Shooting",
columns = c(`X3FG_Text`, `X3FG.`, PER_GAME)
) %>%
# Format column labels
cols_label(
logo_url = "", # No header text for the logo column
TEAM = "TEAM",
`X3FG_Text` = "3FG", # Use the text column for display
`X3FG.` = "3FG%",
PER_GAME = "PER GAME",
SEED = "SEED",
ROUND = "ROUND",
YEAR = "YEAR"
) %>%
# Format the percentage column
fmt_percent(
columns = `X3FG.`,
decimals = 2,
scale_values = FALSE # Values are already 0-100
) %>%
# Format the 'PER GAME' column to two decimal places
fmt_number(
columns = PER_GAME,
decimals = 2
) %>%
# Replace NA values with "???"
sub_missing(
columns = c(SEED, ROUND),
missing_text = "???"
) %>%
# Align columns (optional, but often improves appearance)
cols_align(
align = "center",
columns = c(`X3FG_Text`, `X3FG.`, PER_GAME, SEED, ROUND, YEAR)
) %>%
cols_align(
align = "left",
columns = TEAM
) %>%
# Highlight the Indiana row (using a light blue background as an example)
tab_style(
style = cell_fill(color = "#ADD8E6"), # AliceBlue, adjust as needed
locations = cells_body(rows = TEAM == "Indiana")
) %>%
tab_style(
style = cell_borders(
sides = c("top", 'bottom',"left", "right"), # Or "top", "left", "right", or "all"
color = "black", # Or a hex code
style = "dotted", # Or "dashed", "dotted", "double", "hidden"
weight = px(2) # Default is 1px
), # AliceBlue, adjust as needed
locations = cells_body(columns = `X3FG.`)
) %>%
# Add the source note
tab_source_note(
source_note = "Viz. + Analysis by @andreweatherman"
)%>%
# Adjust width of the logo column if needed (optional)
cols_width(
logo_url ~ px(40) # Set logo column width to 40 pixels
)
gt_table| History does not bode well for the Hoosiers | |||||||
|---|---|---|---|---|---|---|---|
| Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024. | |||||||
| TEAM |
Shooting
|
SEED | ROUND | YEAR | |||
| 3FG | 3FG% | PER GAME | |||||
 |
Wake Forest | 17-61 | 27.87% | 2.83 | 4 | R64 | 2009 |
 |
Indiana | 19-79 | 24.05% | 3.17 | ??? | ??? | 2024 |
 |
North Carolina | 20-60 | 33.33% | 3.33 | 6 | R32 | 2014 |
 |
Coppin St. | 21-60 | 35.00% | 3.50 | 16 | R68 | 2008 |
 |
Vermont | 22-89 | 24.72% | 3.67 | 16 | R64 | 2010 |
 |
New Mexico St. | 22-72 | 30.56% | 3.67 | 13 | R64 | 2014 |
| Viz. + Analysis by @andreweatherman | |||||||
library(magick)
# Read the image
img <- image_read("images/my screenshots.png")
# Display the image to inspect it (optional, opens in a viewer)
#image_browse(img)# Get image dimensions
img_info <- image_info(img)
print(img_info)# A tibble: 1 × 7
format width height colorspace matte filesize density
<chr> <int> <int> <chr> <lgl> <int> <chr>
1 PNG 1066 872 sRGB TRUE 983185 57x57 # Crop a 50x50 pixel section from the Indiana row background
# Adjust coordinates based on your image dimensions
img_cropped <- image_crop(img, "50x50+200+400")
# Display the cropped section to confirm (optional)
#image_browse(img_cropped)# Convert the cropped image to a raster
img_raster <- as.raster(img_cropped)
# Convert the raster to a matrix of colors
img_matrix <- as.matrix(img_raster)
# Extract RGB values from the matrix
# col2rgb expects a vector of colors, so we flatten the matrix
rgb_values <- col2rgb(img_matrix)
# Calculate the average RGB values (to approximate the dominant background color)
avg_rgb <- rowMeans(rgb_values, na.rm = TRUE)
# Convert the average RGB to Hex
# col2rgb returns values in the range 0-255, so we can use them directly
hex_code <- rgb(avg_rgb[1], avg_rgb[2], avg_rgb[3], maxColorValue = 255)
# Print the Hex code
print(hex_code)[1] "#70AACA"# 2. Create the gt table
gt_table <- hoosiers_data %>%
gt() %>%
# --- Add Logos ---
gt_img_rows(columns = logo_url, height = 25) %>% # Use URL column, set image height
# --- Move logo column ---
cols_move_to_start(columns = logo_url) %>% # Place logo column first
# Add title and subtitle
tab_header(
title = "History does not bode well for the Hoosiers",
subtitle = "Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024."
) %>%
# Create the spanner header over the shooting columns
tab_spanner(
label = "Shooting",
columns = c(`X3FG_Text`, `X3FG.`, PER_GAME)
) %>%
# Format column labels
cols_label(
logo_url = "", # No header text for the logo column
TEAM = "TEAM",
`X3FG_Text` = "3FG", # Use the text column for display
`X3FG.` = "3FG%",
PER_GAME = "PER GAME",
SEED = "SEED",
ROUND = "ROUND",
YEAR = "YEAR"
) %>%
# Format the percentage column
fmt_percent(
columns = `X3FG.`,
decimals = 2,
scale_values = FALSE # Values are already 0-100
) %>%
# Format the 'PER GAME' column to two decimal places
fmt_number(
columns = PER_GAME,
decimals = 2
) %>%
# Replace NA values with "???"
sub_missing(
columns = c(SEED, ROUND),
missing_text = "???"
) %>%
# Align columns (optional, but often improves appearance)
cols_align(
align = "center",
columns = c(`X3FG_Text`, `X3FG.`, PER_GAME, SEED, ROUND, YEAR)
) %>%
cols_align(
align = "left",
columns = TEAM
) %>%
# Highlight the Indiana row (using a light blue background as an example)
tab_style(
style = cell_fill(color = "#70AACA"), # AliceBlue, adjust as needed
locations = cells_body(rows = TEAM == "Indiana")
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(rows = TEAM == "Indiana")
) %>%
### dotted line
tab_style(
style = cell_borders(
sides = c("top"), # Or "top", "left", "right", or "all"
color = "black", # Or a hex code
style = "dotted", # Or "dashed", "dotted", "double", "hidden"
weight = px(3) # Default is 1px
), # AliceBlue, adjust as needed
locations = cells_body(columns = `X3FG.`,rows = TEAM == "Wake Forest") # Apply to Indiana row)
) %>%
### dotted line
tab_style(
style = cell_borders(
sides = c("bottom"), # Or "top", "left", "right", or "all"
color = "black", # Or a hex code
style = "dotted", # Or "dashed", "dotted", "double", "hidden"
weight = px(3) # Default is 1px
), # AliceBlue, adjust as needed
locations = cells_body(columns = `X3FG.`,rows = TEAM == "New Mexico St.")
) %>%
### dotted line
tab_style(
style = cell_borders(
sides = c("left","right"), # Or "top", "left", "right", or "all"
color = "black", # Or a hex code
style = "dotted", # Or "dashed", "dotted", "double", "hidden"
weight = px(3) # Default is 1px
), # AliceBlue, adjust as needed
locations = cells_body(columns = `X3FG.`)
) %>%
# Add the source note
tab_source_note(
source_note = "Viz. + Analysis by @andreweatherman"
)%>%
# Adjust width of the logo column if needed (optional)
cols_width(
logo_url ~ px(40) # Set logo column width to 40 pixels
)
gt_table| History does not bode well for the Hoosiers | |||||||
|---|---|---|---|---|---|---|---|
| Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024. | |||||||
| TEAM |
Shooting
|
SEED | ROUND | YEAR | |||
| 3FG | 3FG% | PER GAME | |||||
|
Wake Forest | 17-61 | 27.87% | 2.83 | 4 | R64 | 2009 |
|
Indiana | 19-79 | 24.05% | 3.17 | ??? | ??? | 2024 |
|
North Carolina | 20-60 | 33.33% | 3.33 | 6 | R32 | 2014 |
|
Coppin St. | 21-60 | 35.00% | 3.50 | 16 | R68 | 2008 |
|
Vermont | 22-89 | 24.72% | 3.67 | 16 | R64 | 2010 |
|
New Mexico St. | 22-72 | 30.56% | 3.67 | 13 | R64 | 2014 |
| Viz. + Analysis by @andreweatherman | |||||||
import polars as pl
import pandas as pd
import numpy as np
from great_tables import GT, md, html, loc, style, px# Import necessary components# 1. Create the Pandas DataFrame
# Using a dictionary preserves column names with special characters/spaces
hoosiers_data = pd.DataFrame({
"TEAM": ["Wake Forest", "Indiana", "North Carolina", "Coppin St.", "Vermont", "New Mexico St."],
"logo_url": [
"https://a.espncdn.com/i/teamlogos/ncaa/500/154.png", # Wake Forest
"https://a.espncdn.com/i/teamlogos/ncaa/500/84.png", # Indiana
"https://a.espncdn.com/i/teamlogos/ncaa/500/153.png", # North Carolina
"https://a.espncdn.com/i/teamlogos/ncaa/500/2154.png", # Coppin St.
"https://a.espncdn.com/i/teamlogos/ncaa/500/261.png", # Vermont
"https://a.espncdn.com/i/teamlogos/ncaa/500/166.png" # New Mexico St.
],
"3FG_Text": ["17-61", "19-79", "20-60", "21-60", "22-89", "22-72"], # Keep original text
"3FG%": [27.87, 24.05, 33.33, 35.00, 24.72, 30.56],
"PER_GAME": [2.83, 3.17, 3.33, 3.50, 3.67, 3.67],
"SEED": [4, np.nan, 6, 16, 16, 13], # Use numpy.nan for missing values
"ROUND": ["R64", np.nan, "R32", "R68", "R64", "R64"],
"YEAR": [2009, 2024, 2014, 2008, 2010, 2014],
})
hoosiers_data_pl=pl.from_pandas(hoosiers_data)# 2. Create the great_tables table (Using lambda for older versions)
# NOTE: This assumes fmt_image and loc.body exist in your version.
# If you get errors on those, your version might be very old.
gt_table = (
GT(data=hoosiers_data_pl)
.fmt_image(columns="logo_url", height=25)
.cols_move_to_start(columns=["logo_url"])
.tab_header(
title="History does not bode well for the Hoosiers",
subtitle="Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024."
)
.tab_spanner(
label="Shooting",
columns=["3FG_Text", "3FG%", "PER_GAME"]
)
.cols_label(
logo_url = "",
TEAM = "TEAM",
**{"3FG_Text": "3FG"},
**{"3FG%": "3FG%"},
PER_GAME = "PER GAME",
SEED = "SEED",
ROUND = "ROUND",
YEAR = "YEAR"
)
.fmt_percent(
columns="3FG%",
decimals=2,
scale_values=False
)
.fmt_number(
columns="PER_GAME",
decimals=2
)
.sub_missing(
columns=["SEED", "ROUND"],
missing_text="???"
)
.cols_align(
align="center",
columns=["3FG_Text", "3FG%", "PER_GAME", "SEED", "ROUND", "YEAR"]
)
.cols_align(
align="left",
columns="TEAM"
)
# Highlight the Indiana row (Using lambda function)
.tab_style(
style=style.fill(color="#70AACA"),
# pandas way Use a lambda function to define the row condition
# locations=[loc.body(rows=lambda x: x["TEAM"] == "Indiana")]
locations=[loc.body(rows=pl.col("TEAM") == "Indiana")]
)
# Make letter bold the Indiana row (Using lambda function)
.tab_style(
style=style.text(weight = "bold"),
# pandas way Use a lambda function to define the row condition
# locations=[loc.body(rows=lambda x: x["TEAM"] == "Indiana")]
locations=[loc.body(rows=pl.col("TEAM") == "Indiana")]
)
# Add the source note
.tab_source_note(
source_note=md("Viz. + Analysis by @andreweatherman")
)
# Adjust width of the logo column
.cols_width(
logo_url = px(40)
)
)# save:
# gt_table.save("hoosiers_table.html")
# To display(In Jupyter):
gt_table # In Jupyter| History does not bode well for the Hoosiers | |||||||
|---|---|---|---|---|---|---|---|
| Only one future tournament team made fewer 3PTs through their first six games than Indiana in 2024. | |||||||
| TEAM | Shooting | SEED | ROUND | YEAR | |||
| 3FG | 3FG% | PER GAME | |||||
|
Wake Forest | 17-61 | 27.87% | 2.83 | 4.0 | R64 | 2009 |
|
Indiana | 19-79 | 24.05% | 3.17 | ??? | ??? | 2024 |
|
North Carolina | 20-60 | 33.33% | 3.33 | 6.0 | R32 | 2014 |
|
Coppin St. | 21-60 | 35.00% | 3.50 | 16.0 | R68 | 2008 |
|
Vermont | 22-89 | 24.72% | 3.67 | 16.0 | R64 | 2010 |
|
New Mexico St. | 22-72 | 30.56% | 3.67 | 13.0 | R64 | 2014 |
| Viz. + Analysis by @andreweatherman | |||||||
Original table:
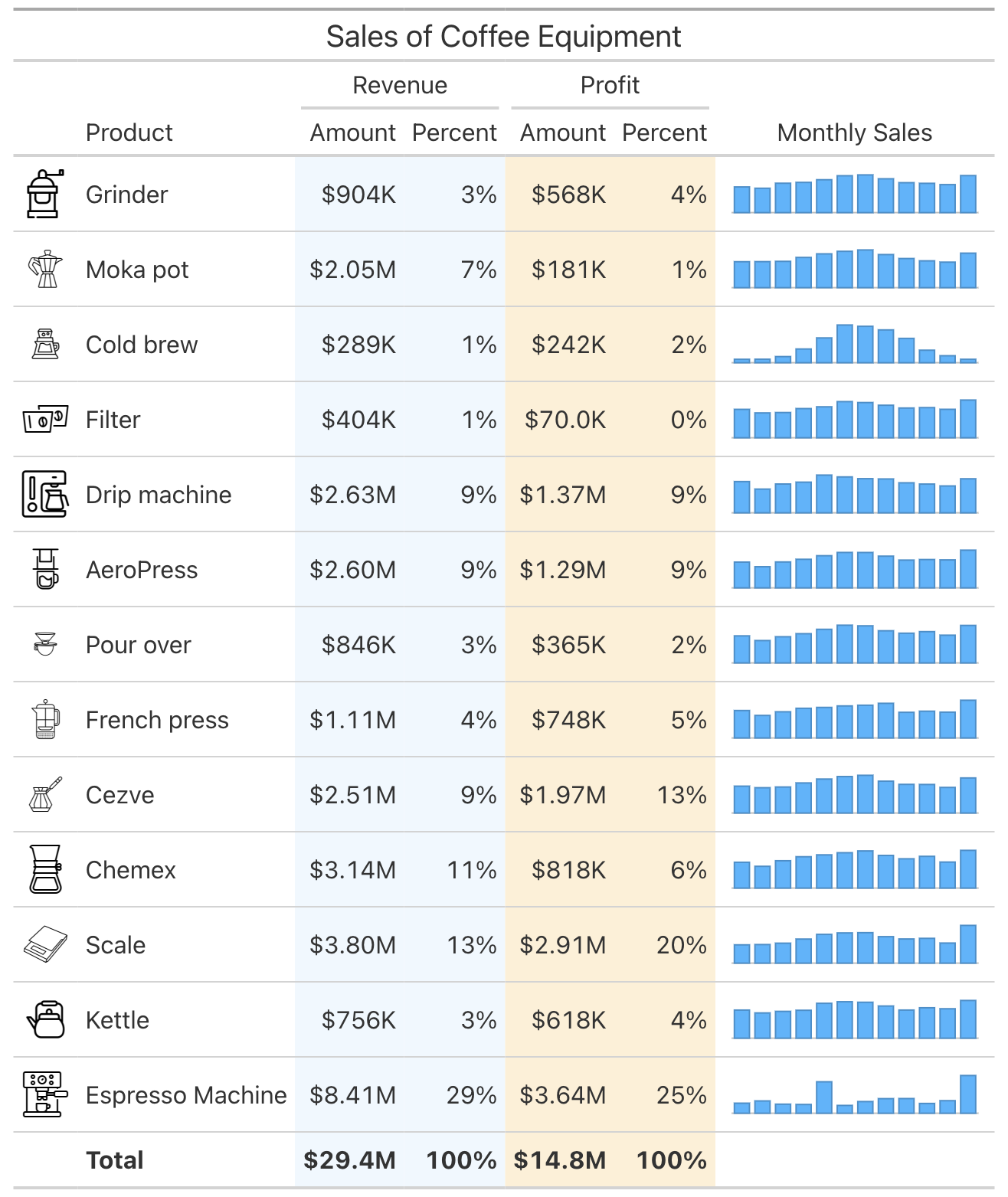
library(gt)
library(gtExtras)
library(dplyr)
library(jsonlite)
library(scales)
library(lubridate)# URL for the data
data_url <- "https://github.com/machow/coffee-sales-data/raw/main/data/coffee-sales.ndjson"
coffee_data_raw =stream_in(url(data_url), simplifyDataFrame = TRUE)
Found 14 records...
Imported 14 records. Simplifying...using R GT package to recreate this table.data source from https://github.com/machow/coffee-sales-data/blob/main/data/coffee-sales.ndjson
Step 1 load package and read in data from github library(gt) library(gtExtras) library(dplyr) library(jsonlite) library(scales) library(lubridate) data_url <- “https://github.com/machow/coffee-sales-data/raw/main/data/coffee-sales.ndjson” coffee_data_raw =stream_in(url(data_url), simplifyDataFrame = TRUE)
no need to no need to Aggregate data for the table.all number are given
Step 2 create GT table,using cols_nanoplot() to add the bar plot for column Monthly Sales
no need to create the icon at left side
Since gt v0.3.0, columns = vars(...) has been deprecated. • Please use columns = c(...) instead.
# Step 1: Load necessary packages
# ----------------------------------------------------
# Ensure gt and gtExtras are installed and loaded
# install.packages("gt")
# install.packages("gtExtras")
library(gt)
library(gtExtras)
library(dplyr) # Still useful for data frame creation/manipulation
library(tibble) # Good for defining data frames
# Step 2: Define the data frame manually based on the image
# ----------------------------------------------------
# Note:
# - Amounts are entered as numbers (e.g., 904000 for $904K, 2.05e6 for $2.05M)
# so fmt_currency(scale_suffixing = TRUE) works correctly.
# - Percentages are entered as proportions (e.g., 0.03 for 3%) for fmt_percent.
# - Monthly Sales data needs to be a list of numeric vectors. Since we don't
# have the exact monthly data, we create approximate data representative
# of the bar patterns shown in the image. The length (14) is arbitrary.
# coffee_table_data <- tibble(
# Product = c("Grinder", "Moka pot", "Cold brew", "Filter", "Drip machine",
# "AeroPress", "Pour over", "French press", "Cezve", "Chemex",
# "Scale", "Kettle", "Espresso Machine"),
# Revenue_Amount = c(904000, 2050000, 289000, 404000, 2630000,
# 2600000, 846000, 1110000, 2510000, 3140000,
# 3800000, 756000, 8410000),
# Revenue_Percent = c(0.03, 0.07, 0.01, 0.01, 0.09,
# 0.09, 0.03, 0.04, 0.09, 0.11,
# 0.13, 0.03, 0.29),
# Profit_Amount = c(568000, 181000, 242000, 70000, 1370000,
# 1290000, 365000, 748000, 1970000, 818000,
# 2910000, 618000, 3640000),
# Profit_Percent = c(0.04, 0.01, 0.02, 0.00, 0.09,
# 0.09, 0.02, 0.05, 0.13, 0.06,
# 0.20, 0.04, 0.25),
# # --- Estimated Monthly Sales Data (List Column) ---
# # Create lists of numbers that approximate the bar patterns
# Monthly_Sales = list(
# c(8,9,8,9,8,9,8,9,8,9,8,9,8,9), # Grinder (Consistent high)
# c(7,8,7,8,7,8,7,8,7,8,7,8,7,8), # Moka pot (Consistent medium-high)
# c(2,3,4,5,6,7,8,7,6,5,4,3,2,1), # Cold brew (Peak in middle)
# c(6,7,6,7,6,7,6,7,6,7,6,7,6,7), # Filter (Consistent medium)
# c(8,9,8,9,8,9,8,9,8,9,8,9,8,9), # Drip machine (Consistent high)
# c(8,9,8,9,8,9,8,9,8,9,8,9,8,9), # AeroPress (Consistent high)
# c(5,6,7,6,5,6,7,6,5,6,7,6,5,6), # Pour over (Slight variation medium)
# c(7,8,7,8,7,8,7,8,7,8,7,8,7,8), # French press (Consistent medium-high)
# c(6,7,8,7,6,7,8,7,6,7,8,7,6,7), # Cezve (Slight variation medium-high)
# c(7,8,9,8,7,8,9,8,7,8,9,8,7,8), # Chemex (Slight variation high)
# c(8,9,8,9,8,9,8,9,8,9,8,9,8,9), # Scale (Consistent high)
# c(7,8,7,8,7,8,7,8,7,8,7,8,7,8), # Kettle (Consistent medium-high)
# c(1,2,3,4,5,6,7,7,6,6,5,5,4,4) # Espresso Machine (Ramp up, plateau/dip)
# )
# )
coffee_table_data=coffee_data_raw |> rename(
Product=product,
Revenue_Amount=revenue_dollars,
Revenue_Percent=revenue_pct,
Profit_Amount=profit_dollars,
Profit_Percent=profit_pct,
Monthly_Sales=monthly_sales
)
# Step 3: Create the GT table
# --------------------------------------------------
coffee_gt_table_manual <- coffee_table_data %>%
# Initialize gt table, using 'Product' column as row labels (stub)
gt(rowname_col = "icon") %>%
# --- Add Column Spanners ---
tab_spanner(
label = "Revenue",
columns = c(Revenue_Amount, Revenue_Percent)
) %>%
tab_spanner(
label = "Profit",
columns = c(Profit_Amount, Profit_Percent)
) %>%
# --- Format Columns ---
# Format Amounts using short scale (K, M)
fmt_currency(
columns = c(Revenue_Amount, Profit_Amount),
currency = "USD", # Assuming USD
decimals = 1, # One decimal place shown in image for totals, apply consistently
suffixing = TRUE # Key for K, M suffixes
) %>%
# Format percentage columns
fmt_percent(
columns = c(Revenue_Percent, Profit_Percent),
decimals = 0 # Zero decimal places
) %>%
# --- Add Nanoplot (Bar Chart) ---
cols_nanoplot(
columns = Monthly_Sales,
plot_type = "bar",
options = nanoplot_options(
data_bar_fill_color = "steelblue",
data_bar_stroke_color = "steelblue"
)
) %>%
# --- Add Grand Summary Row ---
# Calculate sums directly from the numeric columns we created
# Verify these match the totals in the image ($29.4M, 100%, $14.8M, 100%)
# grand_summary_rows(
# columns = c(Revenue_Amount, Profit_Amount),
# fns = list(
# Total = ~sum(., na.rm = TRUE)
# ),
# formatter = fmt_currency,
# #currency = "USD",
# decimals = 1,
# suffixing = TRUE
# ) %>%
# grand_summary_rows(
# columns = c(Revenue_Percent, Profit_Percent),
# fns = list(
# Total = ~sum(., na.rm = TRUE)
# ),
# formatter = fmt_percent,
# decimals = 0
# ) %>%
# --- Add Title and Labels ---
tab_header(
title = "Sales of Coffee Equipment"
) %>%
cols_label(
Revenue_Amount = "Amount",
Revenue_Percent = "Percent",
Profit_Amount = "Amount",
Profit_Percent = "Percent",
Monthly_Sales = "Monthly Sales"
) %>%
# --- Styling ---
cols_width(
c(Product) ~ px(150),
contains("Amount") ~ px(100),
contains("Percent") ~ px(80),
Monthly_Sales ~ px(150)
) %>%
tab_style(
style = cell_text(align = "center", weight = "bold"),
locations = list(
cells_column_spanners(),
cells_column_labels()
)
) %>%
cols_align(
align = "right",
columns = c(Revenue_Amount, Profit_Amount, Revenue_Percent, Profit_Percent)
) %>%
cols_align( # Center align product names (stub) and monthly sales plot
align = "center",
columns = c(Product, Monthly_Sales)
) %>%
cols_align( # Left align product names (stub)
align = "left",
columns = Product
) %>%
tab_options(
column_labels.padding = px(5),
data_row.padding = px(5),
summary_row.padding = px(5), # Controls grand summary padding too
grand_summary_row.padding = px(5)
)# --- Display the table ---
coffee_gt_table_manual |> tab_style(
style= list(cell_fill(color ="aliceblue")),
locations=cells_body(columns = c(Revenue_Amount, Revenue_Percent))
)|> tab_style(
style= list(cell_fill(color ="papayawhip")),
locations=cells_body(columns = c(Profit_Amount, Profit_Percent))
)|> tab_style(
style= list(cell_text(weight="bold")),
locations=cells_body(rows = Revenue_Amount == max(Revenue_Amount))
) |> fmt_image("icon", path="assets") |> sub_missing(missing_text="")| Sales of Coffee Equipment | ||||||
|---|---|---|---|---|---|---|
| Product |
Revenue
|
Profit
|
nanoplots | |||
| Amount | Percent | Amount | Percent | |||
 |
Grinder | $904.5K | 3% | $568.0K | 4% | |
 |
Moka pot | $2.0M | 7% | $181.1K | 1% | |
 |
Cold brew | $288.8K | 1% | $241.8K | 2% | |
 |
Filter | $404.2K | 1% | $70.0K | 0% | |
 |
Drip machine | $2.6M | 9% | $1.4M | 9% | |
 |
AeroPress | $2.6M | 9% | $1.3M | 9% | |
 |
Pour over | $846.0K | 3% | $364.5K | 2% | |
 |
French press | $1.1M | 4% | $748.1K | 5% | |
 |
Cezve | $2.5M | 9% | $2.0M | 13% | |
 |
Chemex | $3.1M | 11% | $817.7K | 6% | |
 |
Scale | $3.8M | 13% | $2.9M | 20% | |
 |
Kettle | $756.2K | 3% | $617.5K | 4% | |
 |
Espresso Machine | $8.4M | 29% | $3.6M | 25% | |
| Total | $29.4M | 100% | $14.8M | 100% | ||
import polars as pl
import polars.selectors as cs
from great_tables import GT, loc, style
coffee_sales = pl.read_ndjson("coffee-sales.ndjson")
sel_rev = cs.starts_with("revenue")
sel_prof = cs.starts_with("profit")
coffee_table = (
GT(coffee_sales)
.tab_header("Sales of Coffee Equipment")
.tab_spanner(label="Revenue", columns=sel_rev)
.tab_spanner(label="Profit", columns=sel_prof)
.cols_label(
revenue_dollars="Amount",
profit_dollars="Amount",
revenue_pct="Percent",
profit_pct="Percent",
monthly_sales="Monthly Sales",
icon="",
product="Product",
)
# formatting ----
.fmt_number(
columns=cs.ends_with("dollars"),
compact=True,
pattern="${x}",
n_sigfig=3,
)
.fmt_percent(columns=cs.ends_with("pct"), decimals=0)
# style ----
.tab_style(
style=style.fill(color="aliceblue"),
locations=loc.body(columns=sel_rev),
)
.tab_style(
style=style.fill(color="papayawhip"),
locations=loc.body(columns=sel_prof),
)
.tab_style(
style=style.text(weight="bold"),
locations=loc.body(rows=pl.col("product") == "Total"),
)
.fmt_nanoplot("monthly_sales", plot_type="bar")
.fmt_image("icon", path="assets")
.sub_missing(missing_text="")
)
coffee_table| Sales of Coffee Equipment | ||||||
|---|---|---|---|---|---|---|
| Product | Revenue | Profit | Monthly Sales | |||
| Amount | Percent | Amount | Percent | |||
|
Grinder | $904K | 3% | $568K | 4% | |
|
Moka pot | $2.05M | 7% | $181K | 1% | |
|
Cold brew | $289K | 1% | $242K | 2% | |
|
Filter | $404K | 1% | $70.0K | 0% | |
|
Drip machine | $2.63M | 9% | $1.37M | 9% | |
|
AeroPress | $2.60M | 9% | $1.29M | 9% | |
|
Pour over | $846K | 3% | $365K | 2% | |
|
French press | $1.11M | 4% | $748K | 5% | |
|
Cezve | $2.51M | 9% | $1.97M | 13% | |
|
Chemex | $3.14M | 11% | $818K | 6% | |
|
Scale | $3.80M | 13% | $2.91M | 20% | |
|
Kettle | $756K | 3% | $618K | 4% | |
|
Espresso Machine | $8.41M | 29% | $3.64M | 25% | |
| Total | $29.4M | 100% | $14.8M | 100% | ||
#coffee_table.save("data/coffee-table.png", scale=2)translate following python code to R code,using cols_nanoplot in R to replace fmt_nanoplot()
Error in fmt_currency(., columns = ends_with(“dollars”), currency = “USD”, : unused arguments (use_sigfig = TRUE, sigfig = 3)
# --- Load necessary libraries ---
library(gt)
library(dplyr)
library(jsonlite)
library(gtExtras)
# --- Data Loading ---
# (Assuming coffee_sales is loaded as before)
con <- file("coffee-sales.ndjson", "r")
coffee_sales <- stream_in(con, simplifyDataFrame = TRUE) %>%
as_tibble()
Found 14 records...
Imported 14 records. Simplifying...close(con)
# --- Table Creation and Styling with gt ---
coffee_table <-
gt(coffee_sales) %>%
# --- Headers and Spanners ---
tab_header(title = "Sales of Coffee Equipment") %>%
tab_spanner(label = "Revenue", columns = starts_with("revenue")) %>%
tab_spanner(label = "Profit", columns = starts_with("profit")) %>%
# --- Column Labels ---
cols_label(
revenue_dollars = "Amount",
profit_dollars = "Amount",
revenue_pct = "Percent",
profit_pct = "Percent",
monthly_sales = "Monthly Sales",
icon = "",
product = "Product"
) %>%
# --- Formatting ---
# *** CORRECTED SECTION ***
# Format numeric columns using significant figures and add '$' prefix with pattern
fmt_number(
columns = ends_with("dollars"),
pattern = "${x}", # Use pattern to add the dollar sign
n_sigfig = 3 , # Specify 3 significant figures
# If you also wanted the compact K/M notation like in Python's compact=True:
suffixing = TRUE
) %>%
# Format percentage columns
fmt_percent(columns = ends_with("pct"), decimals = 0) %>%
# --- Styling ---
tab_style(
style = cell_fill(color = "aliceblue"),
locations = cells_body(columns = starts_with("revenue"))
) %>%
tab_style(
style = cell_fill(color = "papayawhip"),
locations = cells_body(columns = starts_with("profit"))
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = everything(), rows = product == "Total")
) %>%
# --- Special Formatting ---
#gt_plt_bar(column = monthly_sales, color="grey", background = "lightgrey") %>%
# text_transform(
# locations = cells_body(columns = icon),
# fn = function(x) {
# image_path <- file.path("assets", x)
# if (!file.exists(image_path)) {
# warning("Image file not found: ", image_path)
# return("")
# }
# local_image(filename = image_path, height = px(25))
# }
# ) %>%
sub_missing(missing_text = "")
# --- Save the table (optional) ---
# gtsave(coffee_table, filename = "data/coffee-table.png", zoom = 2)# --- Display the table ---
coffee_table|> fmt_image("icon", path="assets") |>
# --- Add Nanoplot (Bar Chart) ---
cols_nanoplot(
columns = monthly_sales,
plot_type = "bar",
options = nanoplot_options(
data_bar_fill_color = "steelblue",
data_bar_stroke_color = "steelblue"
)
)| Sales of Coffee Equipment | ||||||
|---|---|---|---|---|---|---|
| Product |
Revenue
|
Profit
|
nanoplots | |||
| Amount | Percent | Amount | Percent | |||
|
Grinder | $904K | 3% | $568K | 4% | |
|
Moka pot | $2.05M | 7% | $181K | 1% | |
|
Cold brew | $289K | 1% | $242K | 2% | |
|
Filter | $404K | 1% | $70.0K | 0% | |
|
Drip machine | $2.63M | 9% | $1.37M | 9% | |
|
AeroPress | $2.60M | 9% | $1.29M | 9% | |
|
Pour over | $846K | 3% | $365K | 2% | |
|
French press | $1.11M | 4% | $748K | 5% | |
|
Cezve | $2.51M | 9% | $1.97M | 13% | |
|
Chemex | $3.14M | 11% | $818K | 6% | |
|
Scale | $3.80M | 13% | $2.91M | 20% | |
|
Kettle | $756K | 3% | $618K | 4% | |
|
Espresso Machine | $8.41M | 29% | $3.64M | 25% | |
| Total | $29.4M | 100% | $14.8M | 100% | ||
Original table:
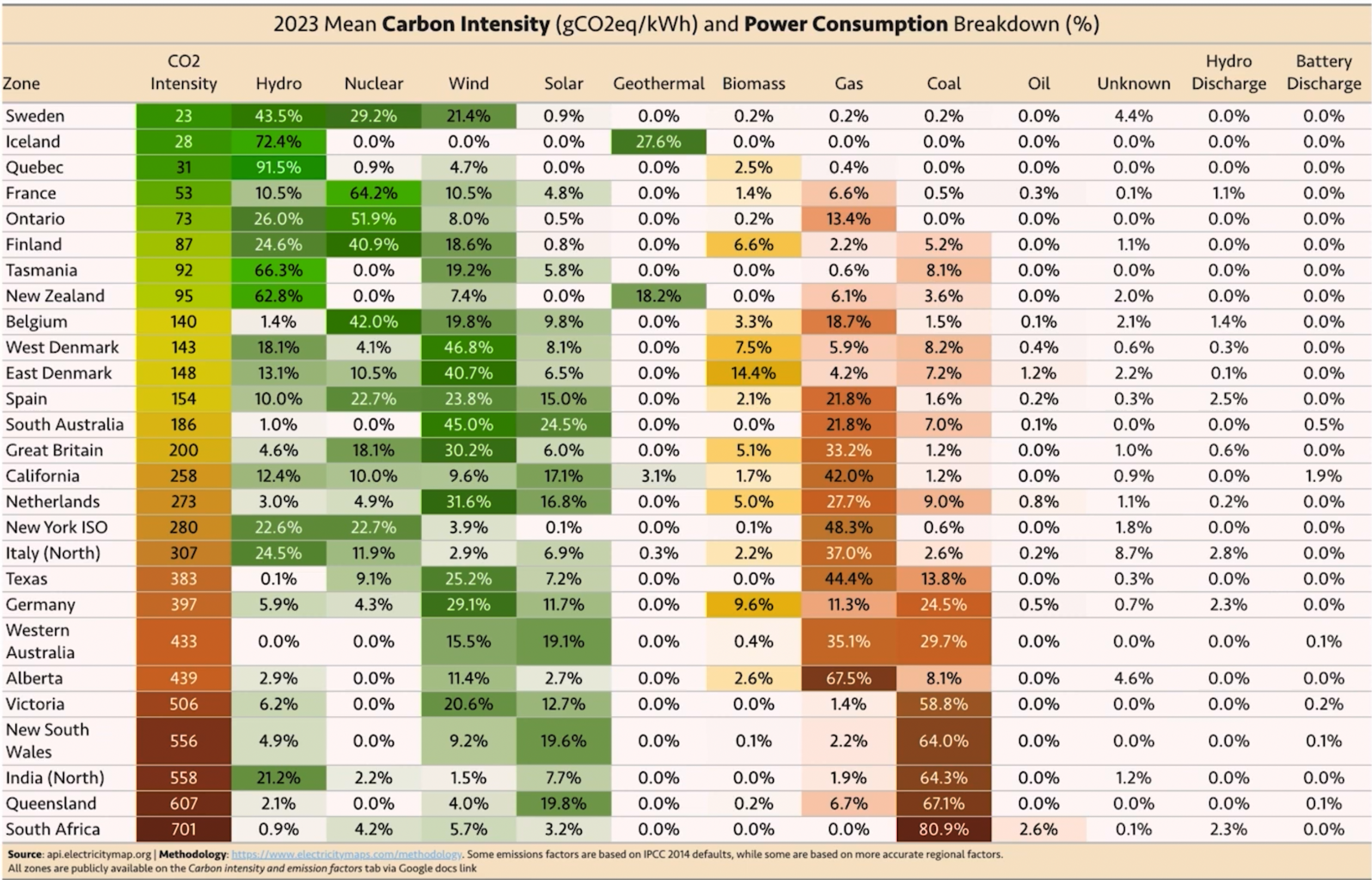
write R code using GT package to recreate this table
1.opt_align change to cols_align 2.cols_labels change to cols_label
library(gt)
library(dplyr)
# Create the data frame (replace with your actual data loading if needed)
data <-read.csv("power-generation.csv")# Create the gt table
gt_table <- data %>%
gt() %>%
# Title and subtitle
tab_header(
title = md("2023 Mean **Carbon Intensity** (gCO2eq/kWh) and **Power Consumption** Breakdown (%)")
) %>%
# Column labels
cols_label(
CO2.Intensity = "CO2 Intensity",
Hydro.Discharge = "Hydro Discharge",
Battery.Discharge = "Battery Discharge"
) %>%
# Format the numeric columns to have one decimal place
fmt_number(
columns = -Zone, # Apply to all columns except Zone
decimals = 1
) %>%
# Add a spanning header for the power consumption breakdown
# tab_spanner(
# label = "Power Consumption Breakdown (%)",
# columns = c(Hydro, Nuclear, Wind, Solar, Geothermal, Biomass, Gas, Coal, Oil, Unknown, Hydro.Discharge, Battery.Discharge)
# ) %>%
# Add source note
tab_source_note(md("Source: [Your Data Source Information Here]")) %>%
# Add a footnote about the methodology
tab_footnote(
md("Some emissions factors are based on IPCC 2014 defaults, while some are based on more accurate regional factors.")
) %>%
# Style the table (optional, customize as needed)
cols_align(align = "center") %>%
opt_row_striping()
# Display the table
gt_table| 2023 Mean Carbon Intensity (gCO2eq/kWh) and Power Consumption Breakdown (%) | |||||||||||||
| Zone | CO2 Intensity | Hydro | Nuclear | Wind | Solar | Geothermal | Biomass | Gas | Coal | Oil | Unknown | Hydro Discharge | Battery Discharge |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sweden | 23.5 | 0.4 | 0.3 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Iceland | 27.6 | 0.7 | 0.0 | 0.0 | 0.0 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Quebec | 30.6 | 0.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| France | 52.7 | 0.1 | 0.6 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Ontario | 72.6 | 0.3 | 0.5 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Finland | 87.2 | 0.2 | 0.4 | 0.2 | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| Tasmania | 92.2 | 0.7 | 0.0 | 0.2 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| New Zealand | 94.5 | 0.6 | 0.0 | 0.1 | 0.0 | 0.2 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Belgium | 139.6 | 0.0 | 0.4 | 0.2 | 0.1 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| West Denmark | 143.1 | 0.2 | 0.0 | 0.5 | 0.1 | 0.0 | 0.1 | 0.1 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| East Denmark | 147.6 | 0.1 | 0.1 | 0.4 | 0.1 | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| Spain | 154.0 | 0.1 | 0.2 | 0.2 | 0.2 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| South Australia | 185.8 | 0.0 | 0.0 | 0.4 | 0.2 | 0.0 | 0.0 | 0.2 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| Great Britain | 199.8 | 0.0 | 0.2 | 0.3 | 0.1 | 0.0 | 0.1 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| California | 257.7 | 0.1 | 0.1 | 0.1 | 0.2 | 0.0 | 0.0 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Netherlands | 272.8 | 0.0 | 0.0 | 0.3 | 0.2 | 0.0 | 0.1 | 0.3 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| New York ISO | 280.0 | 0.2 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Italy (North) | 307.3 | 0.2 | 0.1 | 0.0 | 0.1 | 0.0 | 0.0 | 0.4 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 |
| Texas | 383.2 | 0.0 | 0.1 | 0.3 | 0.1 | 0.0 | 0.0 | 0.4 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| Germany | 396.8 | 0.1 | 0.0 | 0.3 | 0.1 | 0.0 | 0.1 | 0.1 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 |
| Western Australia | 433.3 | 0.0 | 0.0 | 0.2 | 0.2 | 0.0 | 0.0 | 0.4 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 |
| Alberta | 438.9 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.7 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| Victoria | 506.4 | 0.1 | 0.0 | 0.2 | 0.1 | 0.0 | 0.0 | 0.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| New South Wales | 556.3 | 0.0 | 0.0 | 0.1 | 0.2 | 0.0 | 0.0 | 0.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| India (North) | 558.2 | 0.2 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| Queensland | 607.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 0.1 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 |
| South Africa | 701.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 |
| Source: [Your Data Source Information Here] | |||||||||||||
| Some emissions factors are based on IPCC 2014 defaults, while some are based on more accurate regional factors. | |||||||||||||
https://github.com/rich-iannone/great-tables-mini-workshop?tab=readme-ov-file