Code
library(tidyverse)
library(openxlsx)
library(readxl)An overview of Large Language Models (LLMs) and their performance across various benchmarks, including math, code, English, and science.
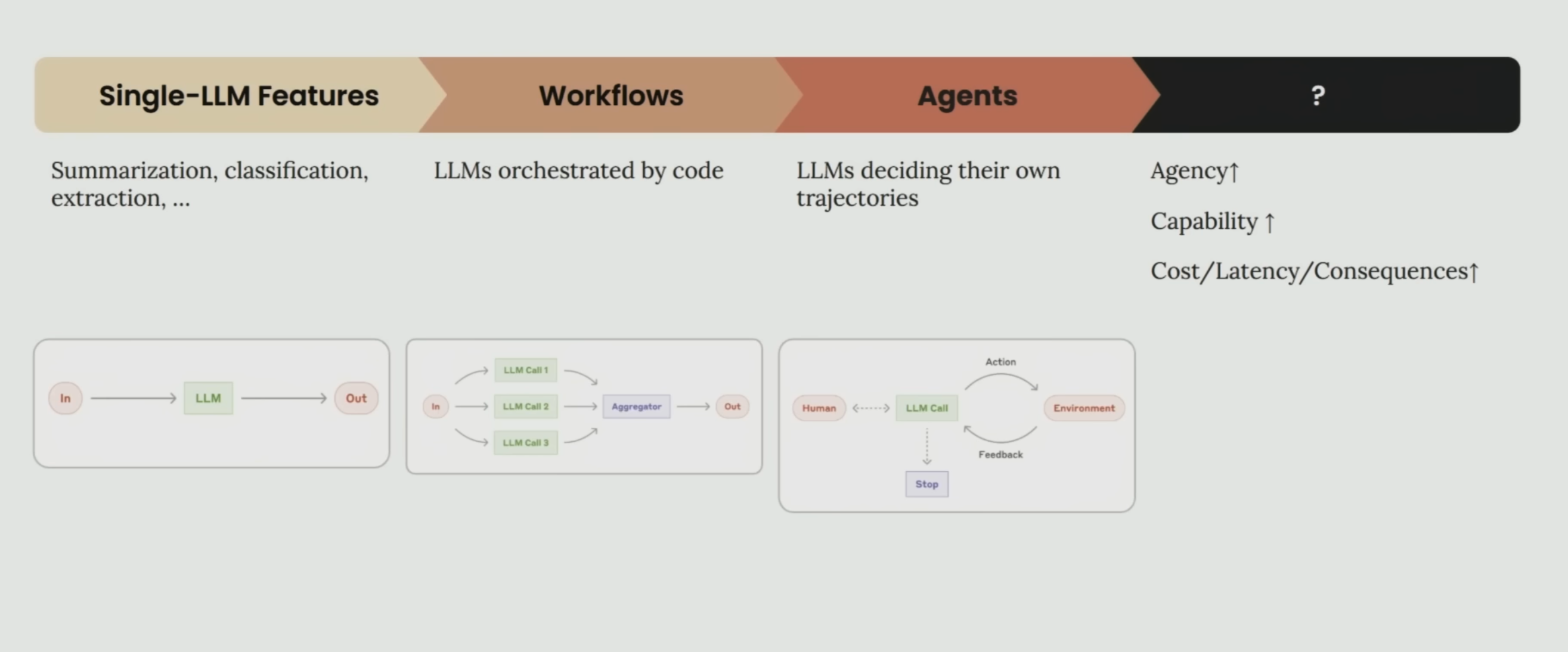
This document provides a comprehensive overview of Large Language Models (LLMs) and their performance across a variety of benchmarks. It categorizes the performance of different models by subject area, including mathematics, coding, English language understanding, and science. The document also provides links to resources where you can compare the performance of different LLM models online.
(LLM)Large language model
library(tidyverse)
library(openxlsx)
library(readxl)data001=read_excel('AI model.xlsx')
head(data001)https://en.wikipedia.org/wiki/American_Invitational_Mathematics_Examination
Measuring Massive Multitask Language Understanding (MMLU)
https://en.wikipedia.org/wiki/MMLU
Graduate-Level Google-Proof Q&A
Description: GPQA consists of 448 multiple-choice questions meticulously crafted by domain experts in biology, physics, and chemistry. These questions are intentionally designed to be high-quality and extremely difficult.
Expert Accuracy: Even experts who hold or are pursuing PhDs in the corresponding domains achieve only 65% accuracy on these questions (or 74% when excluding clear mistakes identified in retrospect).
Google-Proof: The questions are “Google-proof,” meaning that even with unrestricted access to the web, highly skilled non-expert validators only reach an accuracy of 34% despite spending over 30 minutes searching for answers.
AI Systems Difficulty: State-of-the-art AI systems, including our strongest GPT-4 based baseline, achieve only 39% accuracy on this challenging dataset.
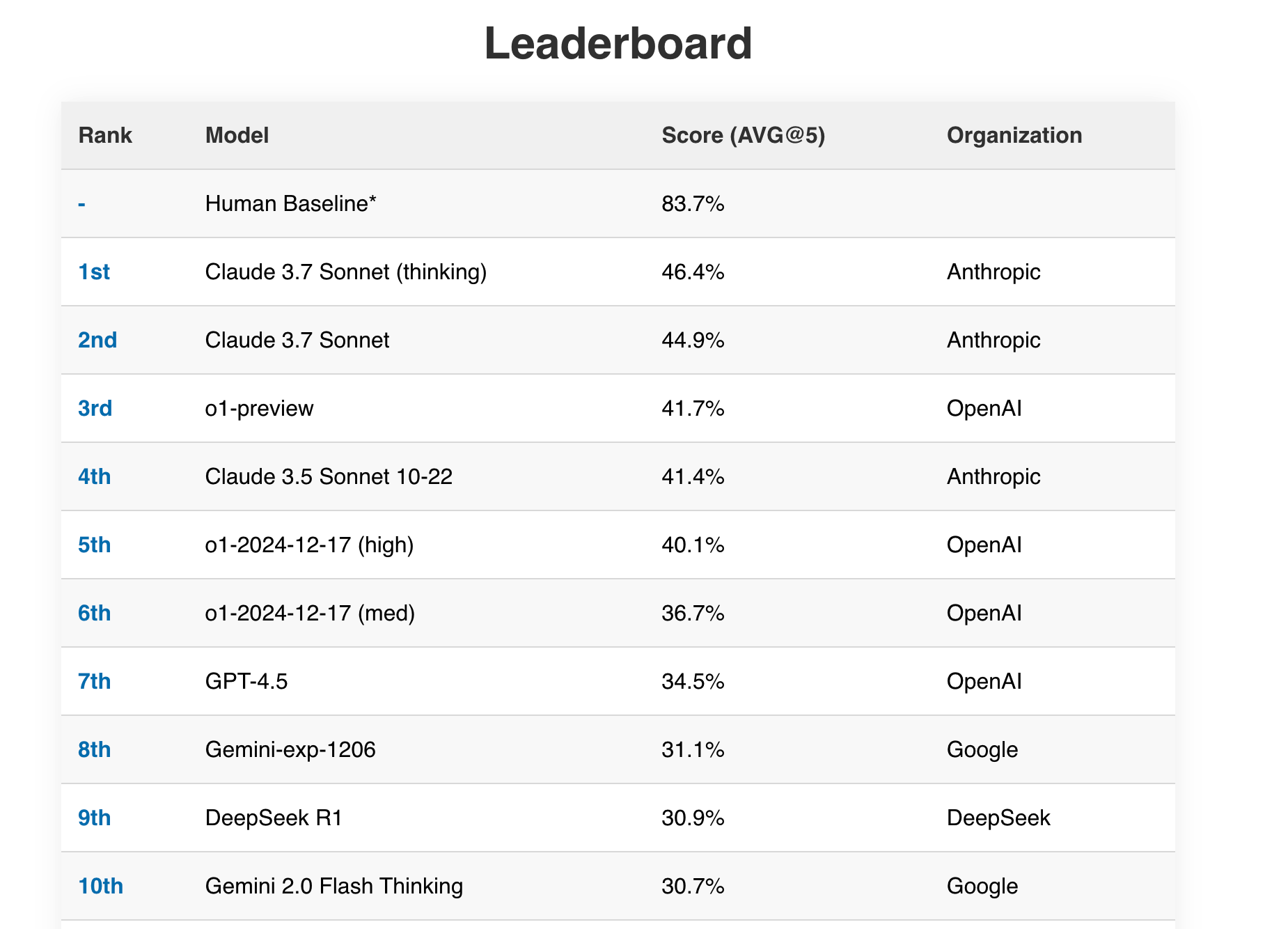
https://simple-bench.com/
 # Compare online
# Compare online
https://lmarena.ai/